Blog


Note
Edit: since this post was written, I have released my Elixir reimplementation of python-greeklish as Greeklix
.
I’m reimplementing python-greeklish
in Elixir and, unlike the original python module, I don’t need to use a lookup table of accented Greek characters and their un-accented equivalents like this:

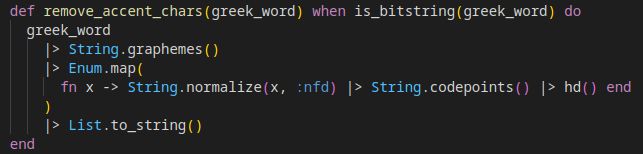
Instead, in Elixir, this function does the trick of removing the accents from accented characters:
x |> String.normalize(:nfd) |> String.codepoints()
And here it is in actual use:
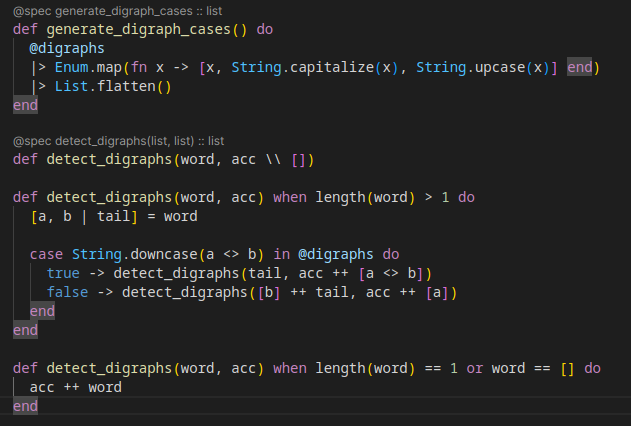
We also don’t need a for-loop for detecting the digraphs, regardless of their case (lowercase, uppercase, capitalized). Instead, we use recursion:
Also, even though this looks cursed, Unicode atoms are valid, hence the digraphs are defined as atoms with Greek characters:
@digraphs [ :αι, :ει, :οι, :ου, :ευ, :αυ, :μπ, :γγ, :γκ, :ντ ]
(Summoning Cthulhu with Greek Elixir atoms.)

Managing Director, OVERBRING Labs
Dipl. Mech. Eng. ETH Zurich, IMD MBA

